

爬虫是按一定规则自动获取互联网数据的过程,几乎每种编程语言都可以实现,之所以使用Python,是因为Python提供了许多简单易用的爬虫库和框架,可以轻松开发一个爬虫程序,下面我简单介绍一下Python爬虫的学习过程,感兴趣的朋友可以尝试一下:
01、Python基础入门这部分主要针对没有任何Python编程基础的开发者,学习Python爬虫,首先,最基础的就是掌握Python的常用语法,包括列表、元组、字典、变量、函数、类、模块、文件操作、异常处理、正则表达式等,至于教程和资料的话,网上就非常多了,B站、慕课网、菜鸟教程等都非常不错,当然,你也可以找一本专业的Python书籍,一边学习一边练习,以掌握和熟悉基础为准:

02、Python爬虫入门基础熟悉后,就是爬虫入门,这里可以先从简单易用、容易学习的爬虫库开始,像urllib、requests、bs4、lxml等都非常不错,官方教程和文档非常详细,只要你熟悉一下使用过程,很快就能掌握的,对于大多数简单的网页或网站来说,都可以轻松爬取:

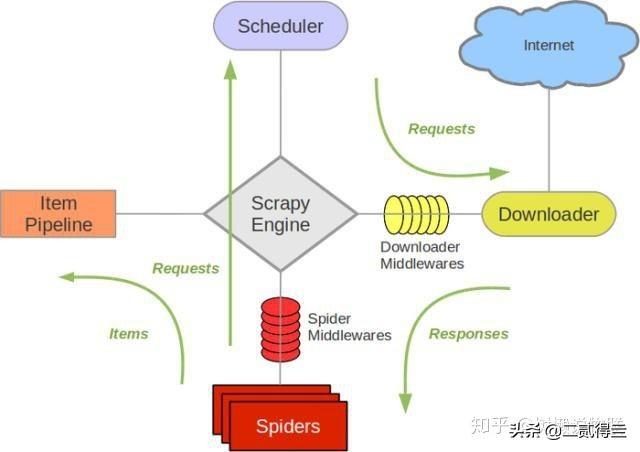
03、Python爬虫框架Python爬虫入门后,为了避免反复造轮子,提高开发效率,这时你就可以学习一些爬虫框架,目前比较流行的就是scrapy,免费、开源、跨平台,可定制化程度非常高,只需添加少量代码就可开启一个爬虫程序,支持分布式,个人学习和使用起来,也非常容易掌握:

目前,就分享这么多吧,Python爬虫入门来说,其实非常容易,只要你多看多练习,很快就能掌握的,后期可以结合pandas、matplotlib、机器学习等做一些处理和分析,网上也有相关教程和资料,介绍的非常详细,感兴趣的话,可以搜一下,希望以上分享的内容能对你有所帮助吧,也欢迎大家评论、留言进行补充。

添加上方▲技术, 在线咨询
复制微信号
声明
一、本站原创内容,其版权属于本网站所有。其他媒体、网站或个人转载使用时不得进行商业性的原版原式的转载,也不得歪曲和篡改本网站所发布的内容。如转载须注明文章来源。
二、本网站转载其它媒体作品的目的在于传递更多信息,并不代表本网站赞同其观点和对其真实性负责;如侵犯你的权益请告诉我们立即删除;其他媒体、网站或个人转载使用自负法律责任。







发表评论
2021-11-14 15:46:23回复
2021-11-14 11:59:03回复