

Python开发爬虫常用的工具总结
reqeusts:Python HTTP网络请求库;
pyquery: Python HTML DOM结构解析库爬虫工具,采用类似JQuery的语法;
BeautifulSoup:python HTML以及XML结构解析;
selenium:Python自动化测试框架爬虫工具,可以用于爬虫;
phantomjs:无头浏览器爬虫工具,可以配合selenium获取js动态加载的内容;
re:python内建正则表达式模块;
fiddler:抓包工具爬虫工具,原理就是是一个代理服务器,可以抓取手机包;
anyproxy:代理服务器爬虫工具,可以自己撰写rule截取request或者response,通常用于客户端采集;
celery:Python分布式计算框架爬虫工具,可用于开发分布式爬虫;
gevent:Python基于协程的网络库爬虫工具,可用于开发高性能爬虫
grequests:异步requests
aio框架

asyncio:python内建异步io爬虫工具,事件循环库
uvloop:一个非常快速的事件循环库爬虫工具,配合asyncio效率极高
concurrent:Python内建用于并发任务执行的扩展
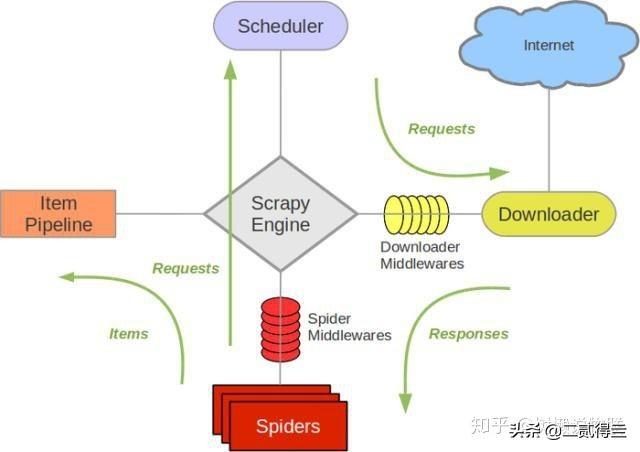
scrapy:python 爬虫框架;
Splash:一个JavaScript渲染服务爬虫工具,相当于一个轻量级的浏览器,配合lua脚本通过他的 解析页面;
Splinter:开源自动化Python web测试工具
pyspider:Python爬虫系统
网页抓取思路
数据是否可以直接从HTML中获取?数据直接嵌套在页面的HTML结构中;
数据是否使用JS动态渲染到页面中的?数据嵌套在js代码中爬虫工具,然后采用js加载到页面或者采用ajax渲染;
获取的页面使用是否需要认证?需要登录后页面才可以访问;
数据是否直接可以通过API得到?有些数据是可以直接通过api获取到爬虫工具,省去解析HTML的麻烦,大多数API都是以JSON格式返回数据;
来自客户端的数据如何采集?例如:微信APP和微信客户端
如何应对反爬
不要太过分爬虫工具,控制爬虫的速率,别把人家整垮了,那就两败俱伤了;
使用代理隐藏真实IP爬虫工具,并且实现反爬;
让爬虫看起来像人类用户爬虫工具,选择性滴设置以下
查看网站的cookie爬虫工具,在某些情况下,请求需要添加cookie用于通过服务端的一些校验;

添加上方▲技术, 在线咨询
复制微信号
声明
一、本站原创内容,其版权属于本网站所有。其他媒体、网站或个人转载使用时不得进行商业性的原版原式的转载,也不得歪曲和篡改本网站所发布的内容。如转载须注明文章来源。
二、本网站转载其它媒体作品的目的在于传递更多信息,并不代表本网站赞同其观点和对其真实性负责;如侵犯你的权益请告诉我们立即删除;其他媒体、网站或个人转载使用自负法律责任。







发表评论
2021-11-23 00:58:03回复