

在数据科学或人工智能领域,除了算法之外,最重要的应该是数据了爬虫工具。甚至可以说一个模型到最后决定其准确度的往往不是算法而是数据。在现实中,缺少足够的数据成了数据分析师获得优秀模型的主要阻碍。可喜的是,现在网络爬虫技术已经相当成熟,一个合格的数据分析师或者人工智能模型设计师应该或多或少熟练掌握几种网络爬虫技术。
Python提供了大量的爬虫库,每个库都有各自不同的特点,而在项目中如何选择适合你的库呢?本文主要列举了5个当前非常流行的Python爬虫库,并列出了各自的优势和劣势,希望可以在你的工作和学习中有所帮助爬虫工具。
Requests库这是Web爬虫最基本的库爬虫工具。 “请求”的意思是向网站的服务器发出HTML请求,以检索其页面上的内容。获取网页的HTML内容是Web爬虫的首要步骤。Requests用于发出各种类型的等。

优点:
使用简单支持基本身份验证支持国际域名和URL支持分块请求支持代理缺点:
只检索页面的静态内容不能用于解析HTML无法处理纯JavaScript制作的网站lxml库Ixml是一种性能较高的HTML和XML的解析库爬虫工具。特别适适合用于大型数据集的爬取解析。通常可以将Requests库和Ixml库结合使用。Ixml还允许你使用XPath和CSS选择器从HTML提取数据。
优点:
速度快爬虫工具,效率高比较轻巧使用元素树支持Pythonic API接口缺点:
不适用于设计不当的HTML官方文档不够详细,不太适合初学者BeautifulSoup库BeautifulSoup库因为其易用性并且非常适合初学者,所以可以说是当前Web爬取中使用最广泛的Python库爬虫工具。BeautifulSoup创建了一个解析树,用于解析HTML和XML文档。BeautifulSoup会自动将输入文档转换为Unicode,将输出文档转换为UTF-8。我们可以将BeautifulSoup与其他解析器(如lxml)结合使用。BeautifulSoup库的一个主要优点是它可以与设计欠佳的HTML一起很好地工作。
优点:
简单爬虫工具,非常简单功能强大文档比较全面特别适合初学者自动编码检测缺点:
性能比lxml慢 Selenium库前面讲到的3种Python库都有一定的局限性,既无法轻易地从动态填充的网站中抓取数据,这是因为动态网站的许多内容是通过JavaScript加载的爬虫工具。换句话说,如果页面不是静态的,那么前面提到的Python库就很难从中抓取数据。Selenium库就是用来解决上述问题。Selenium库最初是用于网络自动化测试的,在其他库无法运行JavaScript的地方,Selenium能够完美的解决。Selenium可以在网页上实现控件点击、填写表格、滚动页面等操作。
优点:
有足够的学习文档爬虫工具,适合初学者自动爬取信息可以抓取动态填充的网页可以在网页上实现与人工相似的任何操作缺点:
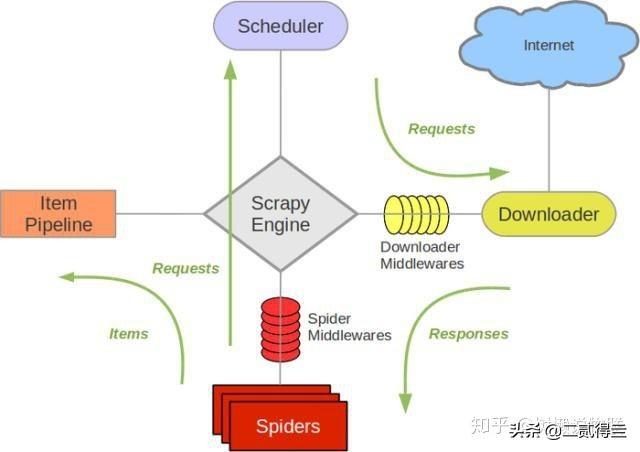
速度非常慢设置比较困难CPU和内存使用率较高不适用于大型项目Scrapy库Python网络爬虫库里的超级大BOSS爬虫工具。Scrapy提供的蜘蛛机器人(spider bots)可以爬取多个网站并提取数据。Scrapy最大的优点是异步爬取,它可以同时发出多个HTTP请求,所以爬取效率很高。
优点:
异步帮助文档较多支持各种插件创建自定义管道和中间件CPU和内存使用率低有大量可用的在线资源缺点:
学习难度比前几种大不适合初学者总结Python网络爬虫库,每个库都是针对不同的使用场景设计的,没有哪个最好,只有哪个更适合你,在使用过程中需要你综合考虑使用场景,毕竟在数据分析的人工智能的世界中往往是性能和计算机资源不可兼得爬虫工具。

添加上方▲技术, 在线咨询
复制微信号
声明
一、本站原创内容,其版权属于本网站所有。其他媒体、网站或个人转载使用时不得进行商业性的原版原式的转载,也不得歪曲和篡改本网站所发布的内容。如转载须注明文章来源。
二、本网站转载其它媒体作品的目的在于传递更多信息,并不代表本网站赞同其观点和对其真实性负责;如侵犯你的权益请告诉我们立即删除;其他媒体、网站或个人转载使用自负法律责任。







发表评论
2021-11-23 02:48:33回复
2021-11-23 01:36:33回复