

群客微信多开微信群多功能营销管理系统(电脑版)-全功能介绍完整版群客助手-微信社群管理助手,依托强大的 AI 智能,实现微信群自管理、自运营,助力您的社群运营营销裂变之路。是微信社群营销不可或缺的工具软件,一款24小时自动运...
网站首页 > idm.org.cn 第64页
-
发布了文章 2022-01-02

置顶群客微信多开微信群营销管理系统-社群助手(电脑版)
-
发布了文章 2022-05-23

置顶微信加好友综合营销电脑版-间隔策略,权重匹配,365天自动加人机器人
微信加好友-微信综合营销系统电脑版-间隔策略,权重匹配,365天自动加人机器人在微信号比软件贵的年代,在企业私域运营管理过程中,软件的安全性,稳定性,可靠性,一直是重中之重!一、当前微信加好友软件存在的问题提 高 通 过 率...
-
发布了文章 2022-06-22

置顶企业微信多开企业微信社群营销管理系统(电脑版)
企业微信社群营销管理系统第三方辅助软件温馨提示:1、所有软件先下载安装(360卫士卸载,电脑软件需关闭系统防火墙),没问题能打开激活码页面再购买激活码! 2、所有软件一经激活,请勿升级系统,或者重装系统,一旦出现问...
-
发布了文章 2025-05-26
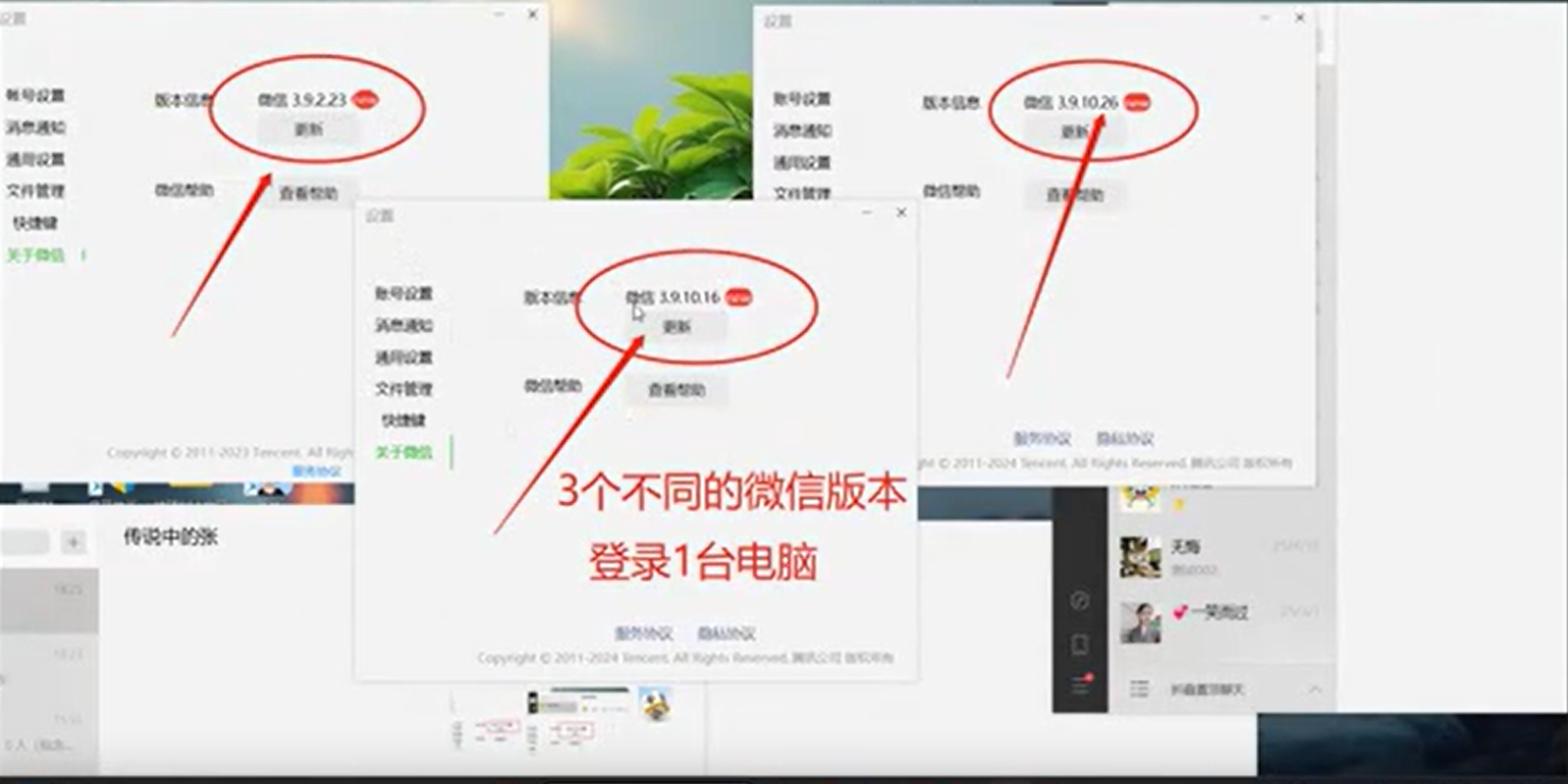
置顶RPA植入新功能:多开助手!基于官方版本,纯物理多开,已支持不同版本多开共存!
RPA植入新功能:多开助手!基于官方版本,已支持不同版本微信多开共存!常见问题:不同微信版本不能共存?不同版本微信如何多开?用了RPA,切换软件,需要下载不同版本微信,安装?解决办法RPA新功能介绍:多开助手使用效果:安全优...
-

外贸老板怎样防止业务员带走客户?
我是磨一剑,外贸资深导师外贸客户管理。让我来回答你的问题。好好看对你有用。作为老板,肯定不希望业务员离职时带走老板。离职带走客户几乎随时可能发生,我们很多时候完全防止是很难做到,但是这么多年外贸经验,我有几个技巧和方法和你一...
-

微商怎么找客源把产品卖出去?
微商主要是通过以下方式把货卖出去的1、创造人微商怎么找客源,也就是流量;微商也就是微信卖货微商怎么找客源,跟淘宝卖货有一个区别,就是流量来源问题,淘宝买东西,都是人有了需求主动去触发,进而产生了一个流量,那么淘宝每天会有几亿...
-

做外贸怎样找客户?
外贸公司怎么找客户找客户?我曾回答过类似问题如:“外贸如何开发客户”和"外贸业务员刚开始可以通过哪些途径接到订单"找客户。一般找客户的渠道分为以下4种:1. 找当地客户办事处很多有一定规模的客户,为了有效...
-
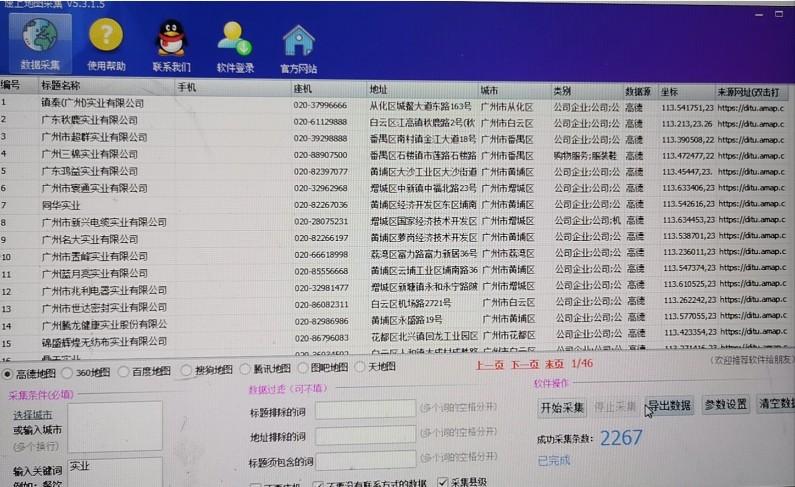
高德地图数据采集数据少按照这个步骤操作
高德地图数据采集数据少按照这个步骤操作:今天有客户反映高德地图数据采集数量突然变少,早上还是正常的,到晚上6点多搜索就不正常了。我们技术测试正常:测试地图:高德地图地区选择:广东省-广州市,刚开始使用软件,地区最好进系统选择...
-

做白酒行业如何找客户?
自国营糖酒公司“统购统销”模式终结以后,白酒渠道就呈现出百花齐放的状态找客户。目前来看,白酒流通渠道主要以流通、酒店、团购、卖场、电商五种形式为主。在此之中,代理商起到了承上启下的关键作用,对于白酒厂家来说,如何寻找到足够多...
-
房地产销售怎么找客户?
你卖房,让我来给你找买房客户,把这么麻烦的事儿交给我,既操心又犯难,朋友实话告诉你吧,我给你找不着,因为现在我所属的地方,房子价格是有,但是有价无市!要想市场价出售,很难,我家亲戚现有楼房出售,都打算卖三年了,还没有卖出去,...
-

做销售如何找客户?
销售的工作跟农民的工作其实是一样的,有一份耕作才有一份收获,如果把销售人员的素质要求排序的话,首先是要勤奋,然后是勤奋,更后还是勤奋,这个说法看起来比较夸张,成功的销售共同的特质就是勤奋,其他的特质各有不同找客户。作为一个新...
-

第一次找客户,你是怎么找到很多客户的?
寻找行业经销商做客户资源池做某个行业分销渠道,花了时间建立一个论坛,全部实名注册,手动认证,专门扫描发布行业内很多公司的更新图册,更新报价单,更新产品的介绍,然后自己写了一些行业内用得到的营销运营技巧方面的短文找客户。加上拷...
-
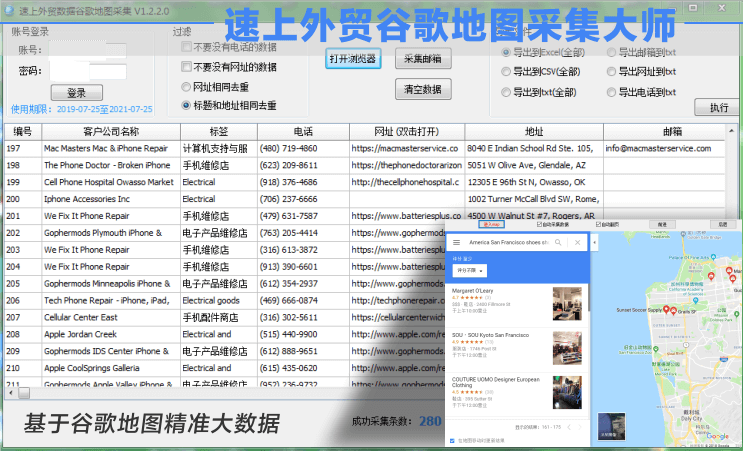
外贸人如何利用谷歌地图精准开发客户?
今年无论的刚做外贸的企业还是传统外贸都面临这一个挑战,由于疫情的原因,展会开发客户模式被迫延缓,线上推广成为新的趋势外贸客户管理。由于很多并没有线上推广的人员和团队,往往在这个过程中会走了很多弯路,这时就需要外贸推广公司来帮...
-

百万级私域用户实战经验分享,用美团用户电话采集带你玩转私域运营
如今,人人都在做私域美团用户电话采集。但私域一直做,有的人却一直落不了地。作者总结了自己过去的项目经验,分享搭建私域用户模型的逻辑和思考,并探讨私域用户池的新玩法。我们一起来看看吧。写本篇文章的目的:总结过去的项目经验;分享...
-

美团点评真的适合培训类商户吗?
不太适合,我朋友就是做培训的跟我反映说带来的学生很少,美团网入驻的机构过多,优先推广付费用户,不花钱很难保证有什么流量,可以考虑入驻A+课堂等垂直类教育分销平台,效果可能会好一些美团商户采集软件。那要看什么类型的培训美团商户...
-

怎样加入美团外卖商户
每个地区的加入美团外卖的方式都是一样的美团商户采集软件。1、可在电脑上登录美团,在美团首页上方的“我是商家-我想合作”中提交信息,如果符合上线标准,工作人员会在7个工作日内联系的美团商户采集软件。提交申请以后,美团网会对商家...
-

美团外卖商家版app如何设置分类?
一:登录美团外卖商家版后台账号密码,或者用手机号验证码登录美团商户采集软件。二:进入美团外卖商家版后台,点击左侧商品管理美团商户采集软件。三:进入商品管理页面,点击要设置菜品的分类美团商户采集软件。四:进入菜品分类,找到对应...
-

美团用户电话采集大数据拓客系统功能详细介绍
美团用户电话采集大数据拓客系统功能详细介绍:1根据地区,行业关键词划分,一键采集客户手机号2可以看一下公司的成立时间,小于5年就不用看了,因为正版的大数据拓客系统都是经过研发,不断地内测,维护,更新,软件稳定之后才能上线的,...
-

驱动增长的私域营销数字化运营体系建设
编辑导语:2021年11月6日至7日,人人都是产品经理举办的【2021产品经理大会(深圳站)】完美落幕美团用户电话采集。华观科技CEO、腾讯云更具价值用户数据专家、《数字突围》作者程刚老师进行了精彩的演讲与分享,此次他分享的...
-

美团外卖App怎么查看商家地址?
美团外卖App是一个生活服务软件,可以在上面查找一些服务,比如外卖、代购等,如果你想去到商家的店面,又不知道它在哪,可以在上面找到它的地址,特别是一些到店自取的商家美团外卖商家电话采集软件。1、打开手机,点开“美团外卖App...
-

怎么通过海关数据来开发客户?客户邮箱与联系方式怎么查找
众所周知,海关数据就是海关履行进出口贸易统计职能中产生的各项进出口统计数据客户联系方式。海关统计的任务是对进出口货物进行调查、分析和监督,提供统计服务。而外贸这个行业又对海关数据极为需要,海关数据的应用在外贸中起着“知己知彼...
-

销售怎样留客户电话?
这个太简单了客户联系方式,不要刻意去问客户要电话,这样客户会有出于本能的防备,一般技巧是在与客户聊天过程中聊的正兴的时候出手!1:引导式 在聊天高潮进入互动情节时说. 您电话是138....的 说的同时拿出手机进行存储,客户...
-
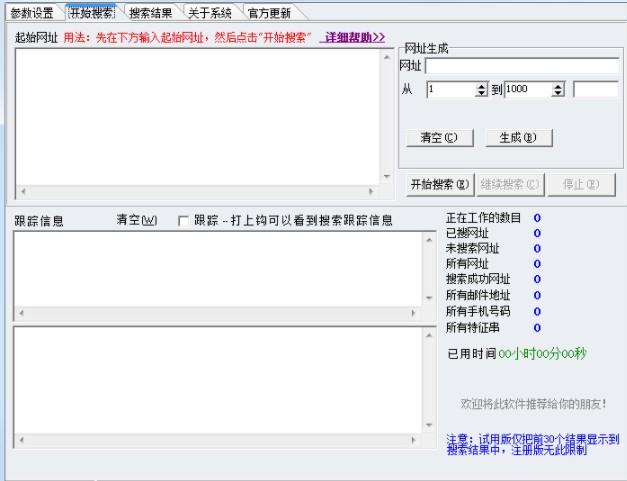
知道客户官方网站,怎么找相关联系人及邮件?
解决一:进入网站后可知道对方公司名称客户联系方式,去公司等查询网站如天眼查查询,里面有相关负责人的联系方式和邮箱等解决二:如果网站联系方式页面那里是个表格客户联系方式,那你鼠标右键点击查看源文件,看看里面有没有邮箱;解决三:...
-

手机里客户的联系方式误删了,怎么恢复?
如何恢复手机联系人?怎样恢复手机联系人?我们一些时候可能会因为自己的不小心将我们的手机联系人给删除客户联系方式,然后自己又不好意思去找别人重新输入,那么我们该怎么办呢?我们是不是可以找回我们的手机联系人呢?我们使用“互盾安卓...
-
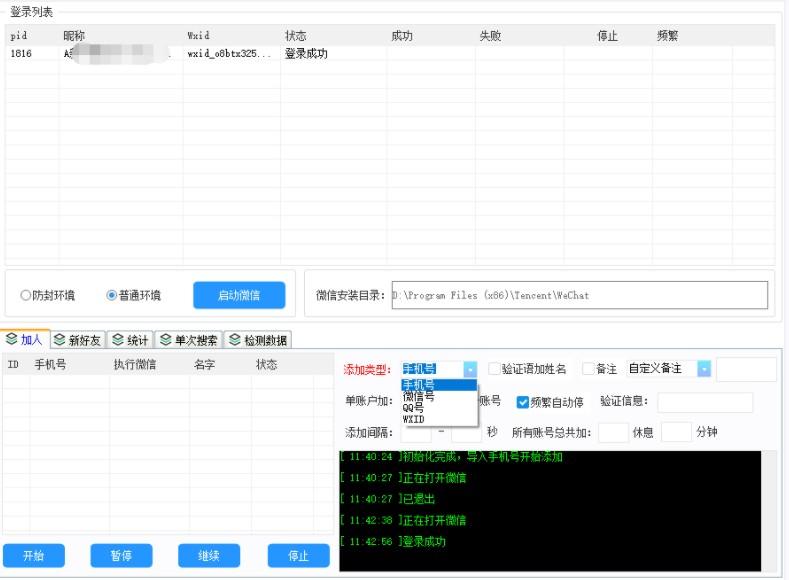
正版通讯录协议5.0,内置检测频繁自动停止防止封号
通讯录协议5.0,内置检测频繁自动停止防止封号,正版支持最新3.4微信软件介绍:支持3.4最新版本微信新增检测频繁自动停止,防止封号新增自定义备注协议批量多微信循环添加手机号/微信号/QQ好友筛选手机号是否开通微信、昵称、男...
-
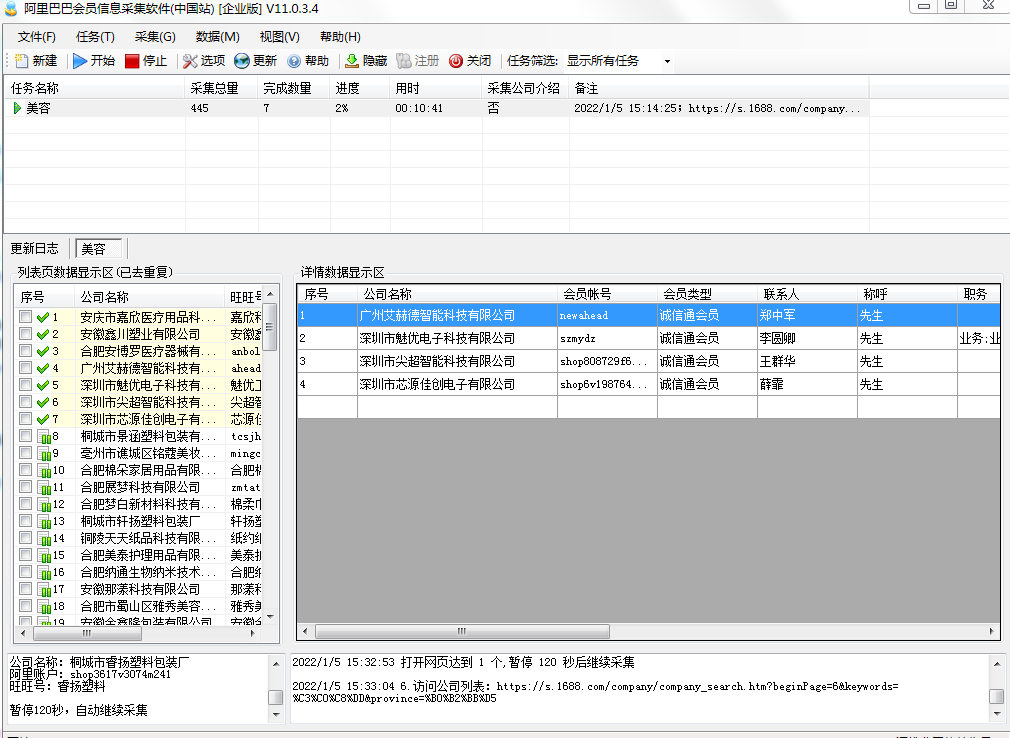
阿里巴巴会员信息采集软件(中国站)-测试
今天我们来测试一款阿里巴巴会员信息采集软件(中国站 我们先来看看阿里巴巴会员信息采集软件(中国站 软件介绍:自动采集阿里巴巴网所有显示企业会员资料;采集内容可按省份、关键词、行业分类自动采集公司名称、联系人、电话、传真号码、...
-
idm.org.cn 2022-01-05

速上数据采集软件是单机版还是多机版本的?
速上数据采集软件是单机版还是多机版本的?我们的电脑版软件都是账号密码登录,并无绑定关系。但是,一个用户在一部电脑上运行,切换另外电脑使用,需要退出账号,并等待服务器账号下线。一般建议登录长期运行的电脑使用。手机软件跟手机有绑...
