

群客微信多开微信群多功能营销管理系统(电脑版)-全功能介绍完整版群客助手-微信社群管理助手,依托强大的 AI 智能,实现微信群自管理、自运营,助力您的社群运营营销裂变之路。是微信社群营销不可或缺的工具软件,一款24小时自动运...
网站首页 > idm.org.cn 第61页
-
发布了文章 2022-01-02

置顶群客微信多开微信群营销管理系统-社群助手(电脑版)
-
发布了文章 2022-05-23

置顶微信加好友综合营销电脑版-间隔策略,权重匹配,365天自动加人机器人
微信加好友-微信综合营销系统电脑版-间隔策略,权重匹配,365天自动加人机器人在微信号比软件贵的年代,在企业私域运营管理过程中,软件的安全性,稳定性,可靠性,一直是重中之重!一、当前微信加好友软件存在的问题提 高 通 过 率...
-
发布了文章 2022-06-22

置顶企业微信多开企业微信社群营销管理系统(电脑版)
企业微信社群营销管理系统第三方辅助软件温馨提示:1、所有软件先下载安装(360卫士卸载,电脑软件需关闭系统防火墙),没问题能打开激活码页面再购买激活码! 2、所有软件一经激活,请勿升级系统,或者重装系统,一旦出现问...
-
发布了文章 2025-05-26
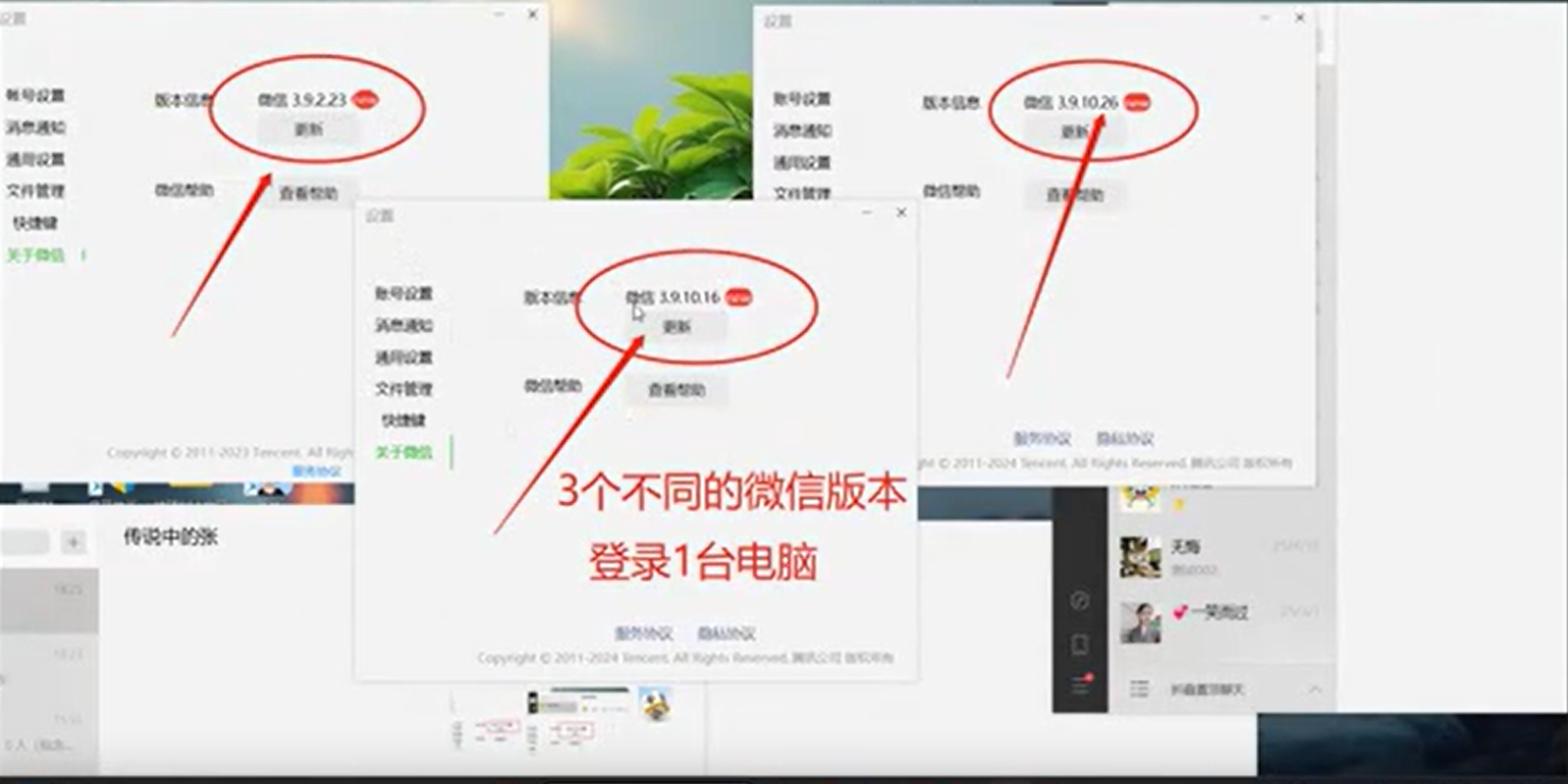
置顶RPA植入新功能:多开助手!基于官方版本,纯物理多开,已支持不同版本多开共存!
RPA植入新功能:多开助手!基于官方版本,已支持不同版本微信多开共存!常见问题:不同微信版本不能共存?不同版本微信如何多开?用了RPA,切换软件,需要下载不同版本微信,安装?解决办法RPA新功能介绍:多开助手使用效果:安全优...
-
idm.org.cn 2022-02-21

美团商家采集软件哪家好_抖音商家采集
做餐饮这么多年,经常听到一些刚创业的老板们不知道收银系统怎么选美团商家采集软件哪家好?因为市面上的收银系统品牌真的太多了。这里提醒各位老板们一句美团商家采集软件哪家好:不要听业务员口吐莲花,选择收银系统坚持最基本的逻辑美团商...
-
idm.org.cn 2022-02-21
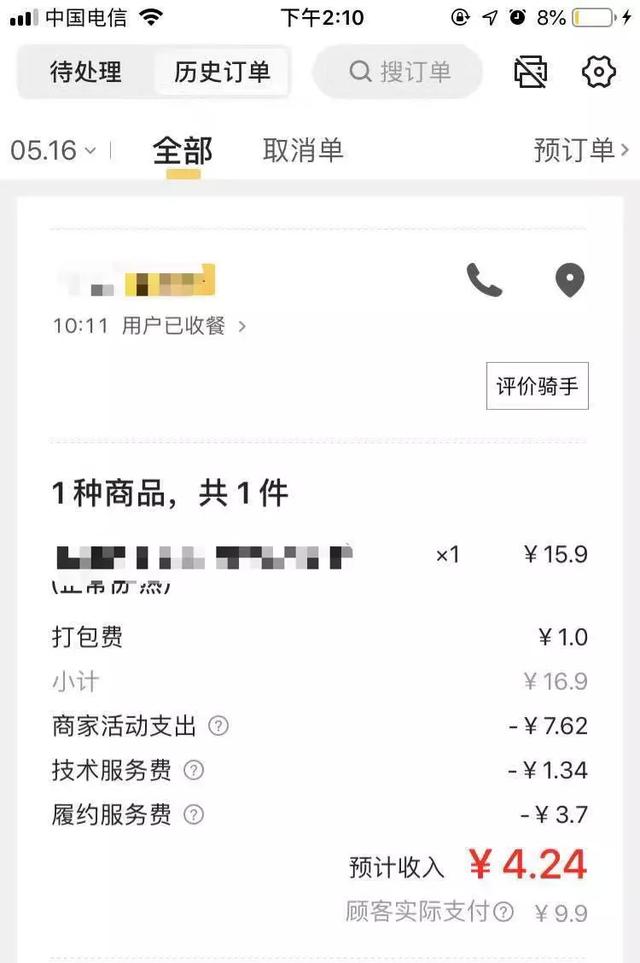
美团采集244个数据收入多少_美团商家实际收入计算
近日,据多个商家告诉AI财经社,美团外卖正在调整商家的抽佣规则。前,商家付给美团的佣金是固定的,大约是订单金额20%左右的比例,名为“平台服务费”。现在,新费率规则把“平台服务费”拆分为“技术服务费+履约服务费”两个名目。技...
-
idm.org.cn 2022-02-20

美团app图片采集_采集美团采集大师
每到一个地方美团app图片采集,先掏出你的手机看看美团app图片采集,没准赚钱的机会就来了 高德淘金 地图淘金 企鹅汇图 美团app图片采集,分别是高德地图,百度地图 跟腾讯地图的 地图采集APP,你可以通过拍照上传地图上没...
-
idm.org.cn 2022-02-20
美团商家采集脚本_美团数据采集软件
从0到1做一个能赚钱的探店抖音号需要多久美团商家采集脚本?三个东北女生给出的答案是美团商家采集脚本:两个月。“孔孔有点冷”“琳琳大王_”“你的楠哥”是毕业于延边大学的三个95后(下文简称孔孔、琳琳和楠哥)美团商家采集脚本,用...
-
idm.org.cn 2022-02-19

采集美团外卖数据_美团外卖怎么看当地排名
导读本文介绍了美团外卖流量数据采集流量数仓的建设以及典型的流量数据应用采集美团外卖数据,其中重点介绍了流量数仓建设过程在建设过程中需要关注的问题以及对应的解决方案 01 流量数据采集。自己搭建了一个啦啦外卖平台采集美团外卖数...
-
idm.org.cn 2022-02-19

美团采集小区楼层信息合法吗_居民楼里开店是否违法
小宝评测是上海市消费者权益保护委员会联合澎湃新闻(www.thepaper.cn)打造的专业评测栏目美团采集小区楼层信息合法吗,关注上海市消保委微信公众号美团采集小区楼层信息合法吗,可以观看更多产品评测内容。同时,小宝评测还...
-
idm.org.cn 2022-02-17
美团采集员审核做什么_美团审核员是做什么的
你正按照地图软件的导航开车美团采集员审核做什么,前方突然没路了,而导航还在叫你继续前行。你抱怨这个地图软件不准确,换了另一个地图软件导航,它规避了这条断头路,你说它很聪明。聪明并不是AI式的聪明,而来自于一群“探路者”。他们...
-
idm.org.cn 2022-02-17

美团优选采集_美团优选采用的是什么模式
关于湖北黄冈黄州区居民违规网上采购进口冷链食品排查处置情况的通报12月8日上午美团优选采集,湖北省疫情防控指挥部通报美团优选采集:武汉市对洪山区昌晶冷链仓储中心进口冷链食品进行新冠病毒核酸监测检测时美团优选采集,...
-
idm.org.cn 2022-02-16

美团网商家网信息采集_美团酒店商家
“尽量打语音美团网商家网信息采集,不要发文字!”“可以放心美团网商家网信息采集,咱们是长期合作,数据都是真实的。”“**宝付款,到时发你邮箱。”《中华人民共和国数据安全法》将于9月1日正式实施,我国网络空间安全治理法律体系将...
-
idm.org.cn 2022-02-16
美团外卖怎么快速采集商家电话_美团外卖店铺菜单采集
(ID美团外卖怎么快速采集商家电话:vittimes)原标题:隔屏有耳,记者耗时3个月测试,美团饿了么是否在“偷听”美团外卖怎么快速采集商家电话?“我的命,我自己操盘”,这是《窃听风云2》中的经典台词,但现实生活中,我们可能...
-
idm.org.cn 2022-02-15
美团信息采集员违法吗_美团拍店合法吗
你正按照地图软件的导航开车美团信息采集员违法吗,前方突然没路了美团信息采集员违法吗,而导航还在叫你继续前行。你抱怨这个地图软件不准确,换了另一个地图软件导航,它规避了这条断头路,你说它很聪明。聪明并不是AI式的聪明,而来自于...
-
idm.org.cn 2022-02-15

美团采集软件_仿美团外卖软件制作
用800平的空间装满惊喜和礼物思议美团采集软件,十余位大咖疯狂输出思议美团采集软件,20+品牌强势助力思议美团采集软件,12月26日,“魔幻”2020年的最后一个周六,21世纪第二个十年的最后一个圣诞节,36氪C端娱乐IP“...
-
idm.org.cn 2022-02-14

美团号码采集软件下载_美团商家数据采集器
4款应用合规测评不足60分。我国《个人信息保护法》于2021年11月1日起施行。法律明确了个人信息处理活动中的权利义务边界美团号码采集软件下载,以“告知—同意”为核心原则对平台进行个人信息处理予以规范。为了解企业在个人信息保...
-
idm.org.cn 2022-02-14
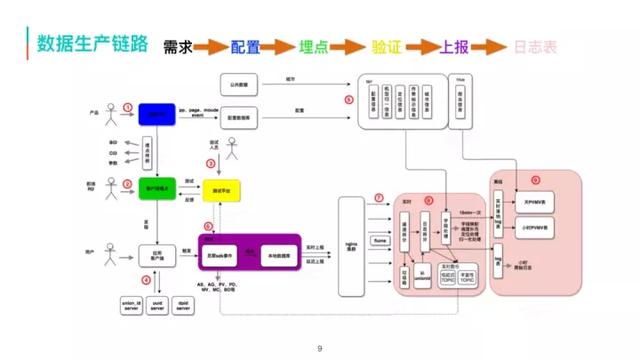
美团app丽人商家电话采集_美团商家信息采集后出售
导读:本文介绍了美团外卖流量数据采集、流量数仓的建设以及典型的流量数据应用美团app丽人商家电话采集,其中重点介绍了流量数仓建设过程、在建设过程中需要关注的问题以及对应的解决方案。01流量数据采集1. 美团外卖流量数据采集历...
-
idm.org.cn 2022-02-13
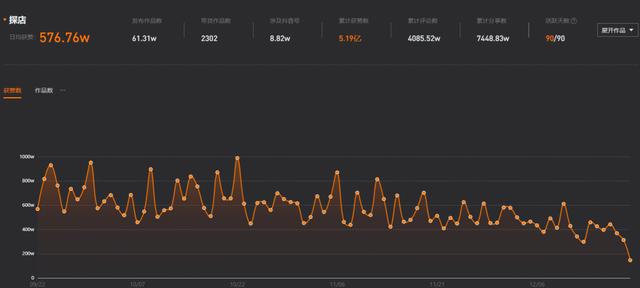
美团商家电话采集器_美团采集软件
从0到1做一个能赚钱的探店抖音号需要多久?三个东北女生给出的答案是美团商家电话采集器:两个月。“孔孔有点冷”“琳琳大王_”“你的楠哥”是毕业于延边大学的三个95后(下文简称孔孔、琳琳和楠哥)美团商家电话采集器,用两个月的时间...
-
idm.org.cn 2022-02-13
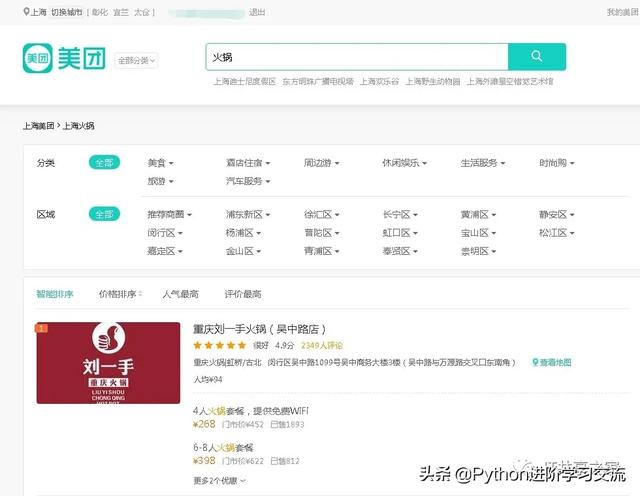
美团定单采集python_美团外卖的爬虫
最近有个小伙伴在群里问美团数据怎么获取美团定单采集python,而且她只要火锅数据,她在上海,只要求抓上海美团火锅的数据,而且要求也不高,只要100条,想做个简单的分析,相关的字段如下图所示。乍一看,这个问题还真的是蛮难的,...
-
idm.org.cn 2022-02-12

美团商家资料采集_美团酒店截图任务
本期核心观点美团点评有一个推广工具叫推广通美团商家资料采集,相当于商家用来购买美团流量用的美团商家资料采集,商家往往会被自己周末生意好的幻想给迷糊住,感觉周末投放美团广告很有用罢了,但实际此时投放广告是最不划算的。大家好,我...
-
idm.org.cn 2022-02-12

美团优惠券采集器_美团上怎么买优惠券
求教美团优惠券采集器,微信公众号哪些饿了么美团优惠券是哪里采集来的之前淘宝也有卖这些优惠券美团优惠券采集器,现在想做网站,想放。美团优惠劵,记得保存美团优惠劵,记得保存图片每天都可以领劵,只需外卖前扫一扫,即可获得优惠了,方...
-
idm.org.cn 2022-02-11
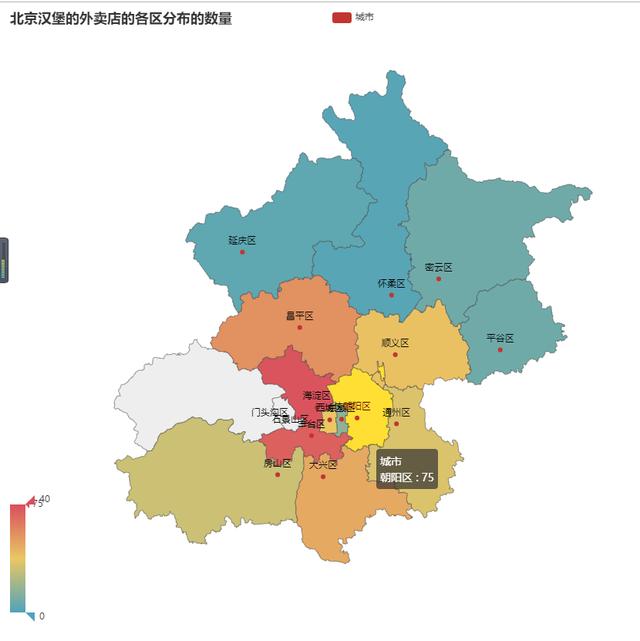
美团外卖数据采集python_美团外卖数据采集器
前言@Author:By Runsen今天肚子饿了美团外卖数据采集python,我突然想点一个外卖,最近迷上了香辣鸡腿堡,打开美团外卖竟然发现周围没有店家, 有的店家离我...
-
idm.org.cn 2022-02-11

美团图片免费采集软件_美团商家电话采集
在11月11日被商家打造成双11购物节后美团图片免费采集软件,原本寓意更早的“光棍节”反而被人淡忘。当很多人在网上“买买买”时美团图片免费采集软件,有一群年轻人依然在为“脱单”努力着,近来走红的脱单盲盒便成了新尝试。在万物皆...
-
idm.org.cn 2022-02-10

美团店铺采集软件_美团评论查询软件
美团拍店是美团旗下的数据采集应用美团店铺采集软件,主要收集各种商业门店美团店铺采集软件,方便美团推广。这个应用主要基于用户的地理位置来引导用户拍摄所在地的商户,拍摄商户后,提交到平台,审核通过后得到相应的奖励,平时走路,闲...
-
idm.org.cn 2022-02-10

大众美团酒店采集截图兼职_美团酒店风控多久解除
【文/观察者网 张照栋】现如今大众美团酒店采集截图兼职,外卖平台究竟为骑手承担了多少责任?认劳率1%。这是北京致诚农民工法律援助与研究中心对1907份有效判决进行研究后得出的数字。也就是说大众美团酒店采集截图兼职,在外卖平台...
-
idm.org.cn 2022-02-09

美团点评信息采集员_美团商家采集
2021年10月美团点评信息采集员,北京街头的便利蜂门店。 (视觉中国/图)这是一场颇具科幻意味的试验美团点评信息采集员,一家名为便利蜂的连锁经营便利店正在研发一套算法,从选址、订货、物流、陈列,甚至打扫卫生,都...
