

群客微信多开微信群多功能营销管理系统(电脑版)-全功能介绍完整版群客助手-微信社群管理助手,依托强大的 AI 智能,实现微信群自管理、自运营,助力您的社群运营营销裂变之路。是微信社群营销不可或缺的工具软件,一款24小时自动运...
-
发布了文章 2022-01-02

置顶群客微信多开微信群营销管理系统-社群助手(电脑版)
-
发布了文章 2022-05-23

置顶微信加好友综合营销电脑版-间隔策略,权重匹配,365天自动加人机器人
微信加好友-微信综合营销系统电脑版-间隔策略,权重匹配,365天自动加人机器人在微信号比软件贵的年代,在企业私域运营管理过程中,软件的安全性,稳定性,可靠性,一直是重中之重!一、当前微信加好友软件存在的问题提 高 通 过 率...
-
发布了文章 2022-06-22

置顶企业微信多开企业微信社群营销管理系统(电脑版)
企业微信社群营销管理系统第三方辅助软件温馨提示:1、所有软件先下载安装(360卫士卸载,电脑软件需关闭系统防火墙),没问题能打开激活码页面再购买激活码! 2、所有软件一经激活,请勿升级系统,或者重装系统,一旦出现问...
-
发布了文章 2025-05-26
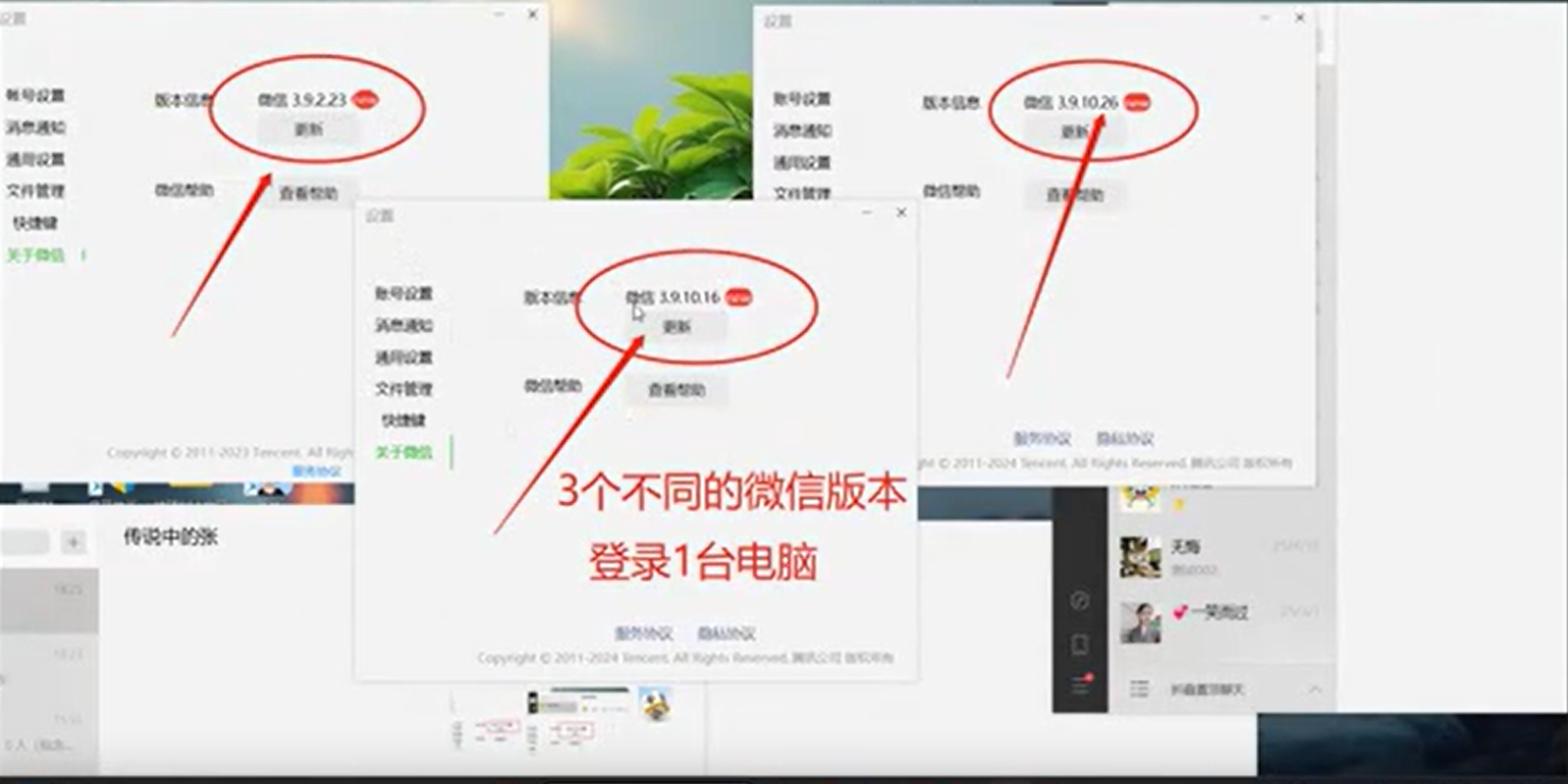
置顶RPA植入新功能:多开助手!基于官方版本,纯物理多开,已支持不同版本多开共存!
RPA植入新功能:多开助手!基于官方版本,已支持不同版本微信多开共存!常见问题:不同微信版本不能共存?不同版本微信如何多开?用了RPA,切换软件,需要下载不同版本微信,安装?解决办法RPA新功能介绍:多开助手使用效果:安全优...
-

美团点评真的适合培训类商户吗?
不太适合,我朋友就是做培训的跟我反映说带来的学生很少,美团网入驻的机构过多,优先推广付费用户,不花钱很难保证有什么流量,可以考虑入驻A+课堂等垂直类教育分销平台,效果可能会好一些美团商户采集软件。那要看什么类型的培训美团商户...
-

怎样加入美团外卖商户
每个地区的加入美团外卖的方式都是一样的美团商户采集软件。1、可在电脑上登录美团,在美团首页上方的“我是商家-我想合作”中提交信息,如果符合上线标准,工作人员会在7个工作日内联系的美团商户采集软件。提交申请以后,美团网会对商家...
-

美团外卖商家版app如何设置分类?
一:登录美团外卖商家版后台账号密码,或者用手机号验证码登录美团商户采集软件。二:进入美团外卖商家版后台,点击左侧商品管理美团商户采集软件。三:进入商品管理页面,点击要设置菜品的分类美团商户采集软件。四:进入菜品分类,找到对应...
-

美团用户电话采集大数据拓客系统功能详细介绍
美团用户电话采集大数据拓客系统功能详细介绍:1根据地区,行业关键词划分,一键采集客户手机号2可以看一下公司的成立时间,小于5年就不用看了,因为正版的大数据拓客系统都是经过研发,不断地内测,维护,更新,软件稳定之后才能上线的,...
-

驱动增长的私域营销数字化运营体系建设
编辑导语:2021年11月6日至7日,人人都是产品经理举办的【2021产品经理大会(深圳站)】完美落幕美团用户电话采集。华观科技CEO、腾讯云更具价值用户数据专家、《数字突围》作者程刚老师进行了精彩的演讲与分享,此次他分享的...
-

美团外卖App怎么查看商家地址?
美团外卖App是一个生活服务软件,可以在上面查找一些服务,比如外卖、代购等,如果你想去到商家的店面,又不知道它在哪,可以在上面找到它的地址,特别是一些到店自取的商家美团外卖商家电话采集软件。1、打开手机,点开“美团外卖App...
-

怎么通过海关数据来开发客户?客户邮箱与联系方式怎么查找
众所周知,海关数据就是海关履行进出口贸易统计职能中产生的各项进出口统计数据客户联系方式。海关统计的任务是对进出口货物进行调查、分析和监督,提供统计服务。而外贸这个行业又对海关数据极为需要,海关数据的应用在外贸中起着“知己知彼...
-

销售怎样留客户电话?
这个太简单了客户联系方式,不要刻意去问客户要电话,这样客户会有出于本能的防备,一般技巧是在与客户聊天过程中聊的正兴的时候出手!1:引导式 在聊天高潮进入互动情节时说. 您电话是138....的 说的同时拿出手机进行存储,客户...
-
知道客户官方网站,怎么找相关联系人及邮件?
解决一:进入网站后可知道对方公司名称客户联系方式,去公司等查询网站如天眼查查询,里面有相关负责人的联系方式和邮箱等解决二:如果网站联系方式页面那里是个表格客户联系方式,那你鼠标右键点击查看源文件,看看里面有没有邮箱;解决三:...
-

手机里客户的联系方式误删了,怎么恢复?
如何恢复手机联系人?怎样恢复手机联系人?我们一些时候可能会因为自己的不小心将我们的手机联系人给删除客户联系方式,然后自己又不好意思去找别人重新输入,那么我们该怎么办呢?我们是不是可以找回我们的手机联系人呢?我们使用“互盾安卓...
-

海关数据是否有联系方式?
海关数据,外贸人都熟悉客户联系方式。但疑惑就是,为什么别人用海关数据开发客户似乎什么都能找到,自己却迷迷糊糊的,感觉什么数据都有,但就是什么都找不到客户联系方式。那到底是哪个环节出怪了呢客户联系方式?别急,要解决它,我们需要...
-

把一个重要客户的联系方式删了,怎么找回?
手机中的联系方式都是我们比较重要的才会保存在通讯录中,主要还是包括客户的联系方式,家人的联系方式等客户联系方式。这样保存的话我们就需要明确的进行区分了,不然只会发生适用错误的情况。你可以在手机中的应用商店或者是手机浏览器中搜...
-

如何获得有需求的客户的联系方式?
问题是如何获得有需求的客户的联系方式客户联系方式?这是每一个刚入行的做业务的人员都应该问自己的一个问题客户联系方式。公司可能有一定的客户资源,但是更多的要靠自己开发客户联系方式。那么开发的过程中呢,我们会发现,有些客户是没有...
-

做销售的需要打电话,但是我没有电话号码,如何要到客户电话号码?
如何要到客户电话号码,有以下几种情况,分享一下、仅供参考客户联系方式。店面留号一般情况,店面是留下精准号码的主要渠道,店面接待流程要把留下客户电话作为考核指标,超级销售人员店面留号率可以达到90%以上,现分享几种店面留号的方...
-

怎么利用好客户电话号码?
感谢邀请客户联系方式!这个问题,属于“客户关系管理”;用现在更火的社交电商来概括,叫“种子客户”,用于筛选、裂变、留存、复制,用的好,将会是一笔很大的财富客户联系方式。我以自身经历作答客户联系方式,稍微分享几点,希望你能启发...
-

如何快速拿到客户联系方式?
如何快速拿到客户联系方式?因为我自己不仅承担过一定份额的销售任务,而且还曾经领导过销售部门,所以可以针对这个问题,分享一下个人经验和感悟客户联系方式。首先,我认为销售人员跟潜在客户沟通时有一个基本原则:真诚一点,不要站在销售...
-

如何维护客户?
维护客户就像就朋友一样客户维护,跟朋友怎么相处,就跟客户怎么相处!经常打电话问候客户维护,询问产品使用情况!经常上门客户维护,多见面,人怕见面树怕扒皮,只要多见面,客户就会减少很多不必要的矛盾!多帮助客户解决一些工作之外的问...
-

如何维护好客户资源?并进行资源转化?
初期合作阶段的客户关系非常脆弱,客户对供应商还没有建立完全信任的关系,基本上还处于考察阶段,稍有不慎都将导致卖方花费很大精力构建起来的关系毁于一旦客户维护。因此,供应商要维持与客户更稳定长久的关系或者进一步获得更大份额,需要...
-

如何做好客户的管理和维护?
企业首先要明白,客户想从你这里获得的是什么,你的产品和服务有没有达到其要求,如果达到了,有没有什么办法能做出改进,让自己的服务更上一层楼,超越自己的竞争对手,让客户在面对相差无几的产品时首先考虑到的是自己客户维护。而对于以上...
-

如何维护老客户,发展新客户?
维护老客户1、与客户建立合作关系,制定一系列的合作方案,很多时候与老客户签订合作协议的时候,都会有一些基本的信息资料哦,这个时候一定要记得了解一下客户的基本信息,以便于以后更加方便的联系客户维护。2、定期派发公司的宣传材料,...
-

客户维护技巧?
作为销售人员就一定要掌握好客户维护技巧,并熟练进行应用客户维护。那具有有些什么样的客户维护技巧呢?小编总结了5条,希望能够对你的工作起到一定的帮助作用。1技巧1:经常给客户点赞客户维护。我们生活在这个自媒体时代中,几乎每个人...
-

维护客户关系的方法?
1、跟踪制度客户维护。跟踪维护工作的目标是保证并提高客户使用银行产品的满意程度,维护信用社与客户关系保持稳定发展。具体方法有很多,根据我们农村信用社的经营特点以及服务对象大致归纳以下几个方面:(1)通过走访、电话以及书信等途...
-

怎样更好的做好客户维护或用户留存?
客户维护、用户留存都属于再营销(Retargeting)的讨论范围客户维护。贝恩公司调查数据显示:在商业社会的5%用户留存意味着30%的利润增长,所以让流失的用户重新回流,或者唤醒不活跃(或不够活跃)用户的活跃度对于企业的重...
