

群客微信多开微信群多功能营销管理系统(电脑版)-全功能介绍完整版群客助手-微信社群管理助手,依托强大的 AI 智能,实现微信群自管理、自运营,助力您的社群运营营销裂变之路。是微信社群营销不可或缺的工具软件,一款24小时自动运...
-
发布了文章 2022-01-02

置顶群客微信多开微信群营销管理系统-社群助手(电脑版)
-
发布了文章 2022-05-23

置顶微信加好友综合营销电脑版-间隔策略,权重匹配,365天自动加人机器人
微信加好友-微信综合营销系统电脑版-间隔策略,权重匹配,365天自动加人机器人在微信号比软件贵的年代,在企业私域运营管理过程中,软件的安全性,稳定性,可靠性,一直是重中之重!一、当前微信加好友软件存在的问题提 高 通 过 率...
-
发布了文章 2022-06-22

置顶企业微信多开企业微信社群营销管理系统(电脑版)
企业微信社群营销管理系统第三方辅助软件温馨提示:1、所有软件先下载安装(360卫士卸载,电脑软件需关闭系统防火墙),没问题能打开激活码页面再购买激活码! 2、所有软件一经激活,请勿升级系统,或者重装系统,一旦出现问...
-
发布了文章 2025-05-26
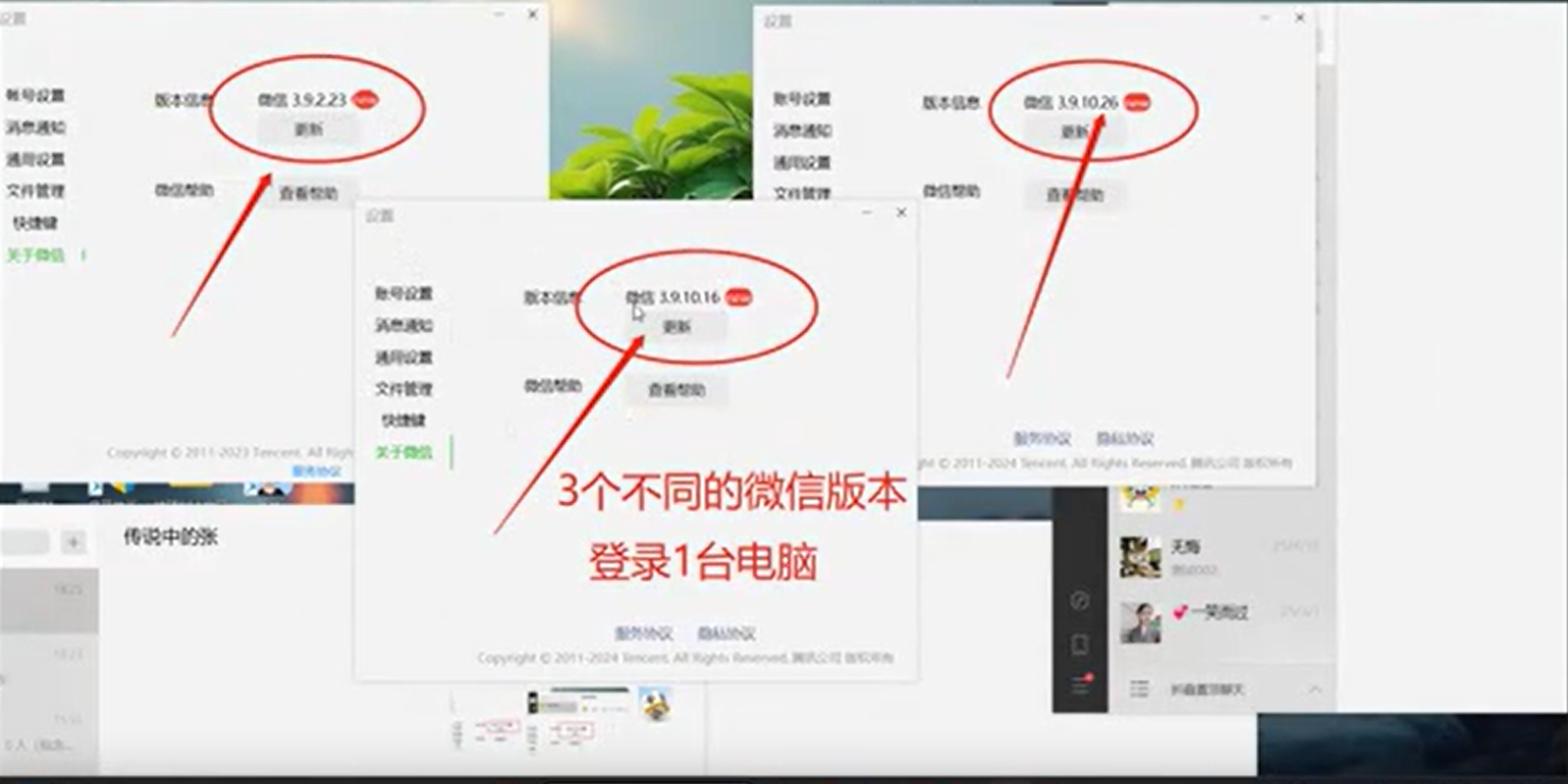
置顶RPA植入新功能:多开助手!基于官方版本,纯物理多开,已支持不同版本多开共存!
RPA植入新功能:多开助手!基于官方版本,已支持不同版本微信多开共存!常见问题:不同微信版本不能共存?不同版本微信如何多开?用了RPA,切换软件,需要下载不同版本微信,安装?解决办法RPA新功能介绍:多开助手使用效果:安全优...
-

客户维护技巧?
作为销售人员就一定要掌握好客户维护技巧,并熟练进行应用客户维护。那具有有些什么样的客户维护技巧呢?小编总结了5条,希望能够对你的工作起到一定的帮助作用。1技巧1:经常给客户点赞客户维护。我们生活在这个自媒体时代中,几乎每个人...
-

维护客户关系的方法?
1、跟踪制度客户维护。跟踪维护工作的目标是保证并提高客户使用银行产品的满意程度,维护信用社与客户关系保持稳定发展。具体方法有很多,根据我们农村信用社的经营特点以及服务对象大致归纳以下几个方面:(1)通过走访、电话以及书信等途...
-

怎样更好的做好客户维护或用户留存?
客户维护、用户留存都属于再营销(Retargeting)的讨论范围客户维护。贝恩公司调查数据显示:在商业社会的5%用户留存意味着30%的利润增长,所以让流失的用户重新回流,或者唤醒不活跃(或不够活跃)用户的活跃度对于企业的重...
-

如何客户维护?
1、了解客户企业必须考虑:客户处于哪个个消费区间,是价值客户、潜力客户、迁移客户,还是冰点客户;客户有哪些显性需求与潜在需求;他们希望通过哪些渠道以怎样的方式来满足;企业有哪些资源能够让客户满意的得到满足;驱动客户产生购买的...
-

销售人员如何维护老客户?
1 建立客户档案库一定要为每一个客户建立客户档案客户维护,客户档案尽可能的详细,越详细越有助于你做关系维护,档案库一般包含哪些信息呢?001 基本信息姓名、职位、公司名称、电话、年龄、籍贯、公司地址、教育背景、生日客户维护。...
-

第一次做生意,怎样维护住客户?
第一次做生意,对初做生意者来说怎样维护住客户是一个非常新颖且必须引起重视的大问题客户维护。既然是第一次做生意,说明之前没有做生意的经验可谈,在这种情况下就应该多听多学借鉴身边生意成功朋友的生意经,特别是在开发和维护客户方面下...
-

怎样收集分析顾客信息?
1、界定目标市场所有的营销活动(包括顾客关系管理)都源自于对目标市场的界定客户信息。随着竞争日益加剧,市场被划分得越来越细。幸运的是,以互联网为主要特征的数字经济有助于企业将顾客进一步进行细分为各个“微观细分市场”(Micr...
-

在淘宝购物的时候,卖家能看到买家的哪些信息?
看到这个问题让我想起了,之前被淘宝卖家骚扰的经历客户信息。当时在某淘宝店买了衣服,结果卖家虚假发货,尝试联系卖家询问原因,联系了整整一周都联系不上。于是,上淘宝维权去投诉它,维权成功的当天半夜0点到2点期间,不短被淘宝卖家恶...
-

客户信息太多怎么办?
客户信息太多一句话没有看懂客户信息。意思是一个客户的信息特别多?还是有许多用户的信息?其实这两点,都代表着好的一方面。如果是一个用户的信息特别多,那么说明你可以给这个用户打出很多不同的标签,找到很多方面的突破口和契合点,可以...
-

客户信息收集?
从问题描述来说,Excel好像就可以满足这个功能,但是如果从长远来看,如果客户量太大,Excel表格显然是不太适合的客户信息。所以用系统也是一个长远的打算。选择软件或系统前的考虑管理客户的软件或系统,很容易让人联想到CRM系...
-

APP数据采集常见方法总结
APP数据采集常见方法总结有代码经验或APP开发的同学都很容易理解,其实很多APP,走的都是webservice通讯协议的方式,并且由于是公开数据,而且大部分是无加密的。所以只要对网络端口进行监测,对APP进行模拟操作,即可...
-

有没有好用的记录客户信息的软件?
现在很多软件往往提供的功能过于全面客户信息,导致很多功能大概90%以上的功能都使用不到,想想你买的手机,商家宣传的那些功能和配置你真正使用的频率才有几次呢?秉着这样的原则,给大家推荐——轻流,产品如其名,对于每个使用过后的人...
-

全球知名制药企业有哪些?
全球知名制药企业有哪些?辉瑞公司-美国赛诺菲公司-法国默沙东公司-美国诺华公司-瑞士葛兰素史克公司(GSK)-英国阿斯利康公司-英国罗氏公司-瑞士百时美施贵宝公司-美国强生公司-美国勃林格殷格翰公司-德国施维雅公司-法国雅培...
-

国内有哪些较好的医药公司?
因为目前A股医药股正处于历史低部,医药股虽然不会象PcB那样披头盖脸地拔高,但部分个股走个慢牛是应该有的医药企业。目前医药股的投资逻辑就是价值洼地、人口多老龄化、带量采购等。A股第一高价医药股是长春高新,现价359元医药企业...
-

世界500强的中国医药公司有哪些?
2019年7月22日,更新一期的《财富》世界500强排行榜,全球共16家医药行业相关企业入榜,其中,中国华润有限公司、中国医药国药两家来自中国医药企业。首先简述一下华润:中国华润的前身是于1938年在香港成立的“联和行”,1...
-

世界前五大制药公司是什么?
世界前五大制药公司依次分别是Pfizer辉瑞公司、GSK葛兰素史克公司 、阿斯利康公司 、强生公司 、默沙东公司Pfizer辉瑞公司是目前全球大医药企业,拥有150多年历史的以研发为基础的跨国制药公司医药企业。2000年6月...
-

医药的龙头企业除了恒瑞医药还有哪些?
医药行业有8大细分领域医药企业,每个细分领域相当于一个赛道,不同的赛道龙头公司都有哪些?一起来看看:1.化学药龙头——恒瑞医药、复星医药、科伦药业核心关键词:研发投入=未来创新力3家龙头公司每年的研发投入在A股所有医药公司中...
-

营销对企业来说有多重要?
传统网站基本上采用的是模版网站或者展示型网站,只是单纯的帮助企业实现网站的基础功能,不会考虑网站在搜索引擎的排名、用户体验、流量的多少、网站的转化率等等企业营销。而营销型网站主要是突出“营销”,以大连网站建设的定位系统、用户...
-

公司销售流动性强,怎么让新入职销售快速上手?
我是喝了蜂蜜的小熊,我想分享企业营销。首先我们排除系统性培训的可能企业营销。销售系统性培训需要的时间比较长,包括企业文化,产品知识、销售意识、销售报告、销售技巧和业绩达成的培训基本不可能一蹴而就。其次排除2B的销售可能企业营...
-

市场营销环境对企业营销有何重要意义?
市场营销环境对企业营销带来双重影响作用:(1)环境给企业营销带来的威胁企业营销。营销环境中会出现许多不利于企业营销活动的因素,由此形成挑战。如果企业不采取相应的规避风险的措施,这些因素会导致企业营销的困难,带来威胁企业营销。...
-

企业如何做好精准营销?
营销,通常都是通过线上及线下平台针对当前企业的产品特色以及使用人群来进行广而告之,这样覆盖率广泛,其实能起到的作用很小;企业之所以需要精准营销,是因为精准营销更有针对性,更一针见血,更能高效捕捉目标客户、降低企业运营成本企业...
-
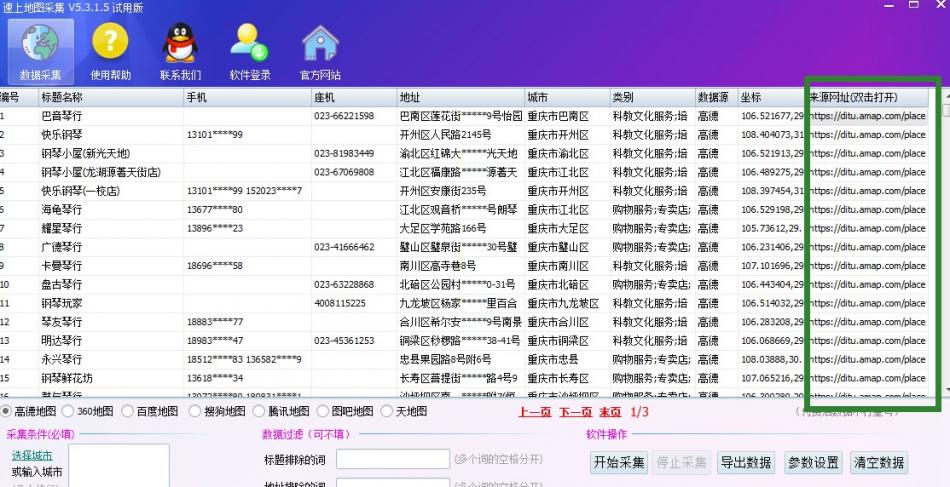
速上地图数据采集软件可以采集导出哪些商家数据?
速上地图数据采集软件可以采集那些数据?试用版下载:速上地图数据采集软件(电脑版) | 软件产品-速上数据采集官网 (idm.org.cn 试用版:无须登录账号,可以直接采集试用,对于采集软件主要试用采集功能,为了更好的提升软...
-

社群运营必备的社群管理工具你用过吗?
社群运营必备的社群管理工具你用过吗?社群运营肯定是需要社群管理工具的,这些工具的运用不但大大降低了人工成本,而且可以使社群管理的数据量化,进行精准管理:· 个人号管理工具:同意好友:自动打招呼吸粉的插件、通过好友后...
